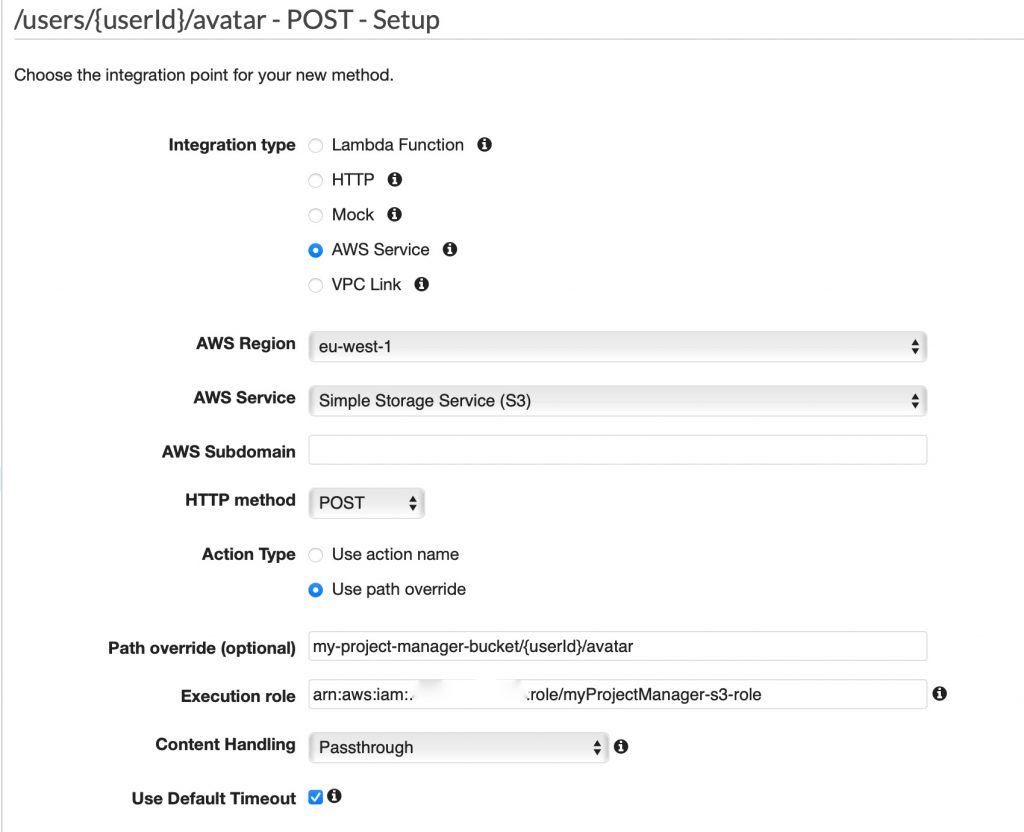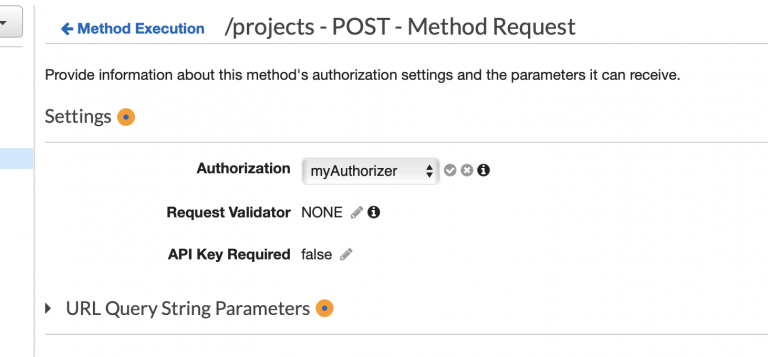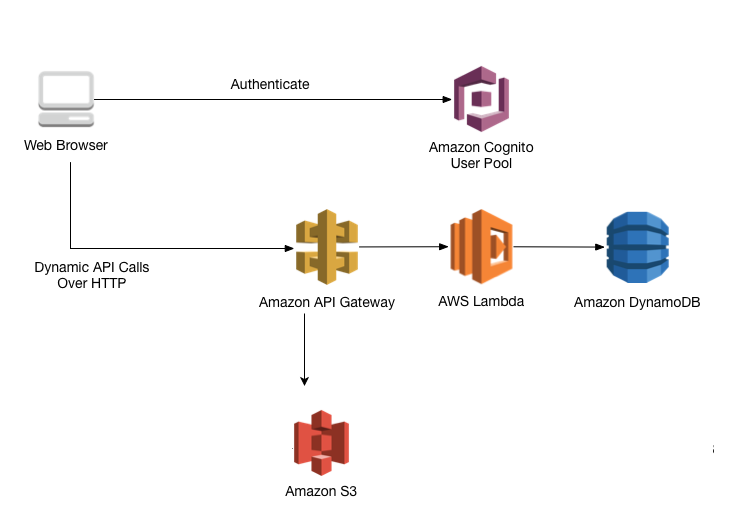
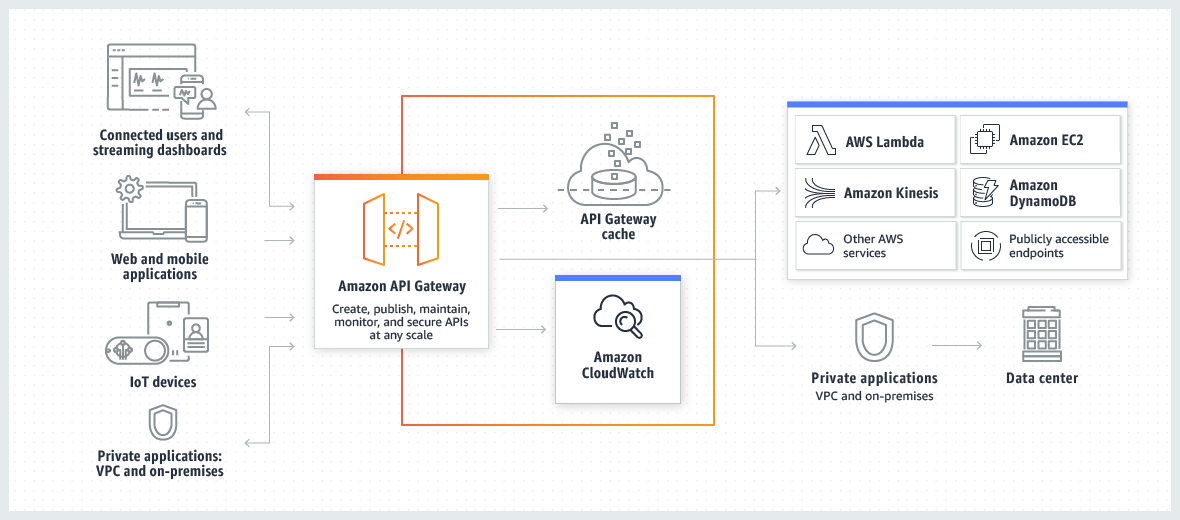


Bucket: Ein Behälter für Objekte, die in Amazon S3 gespeichert werden. Buckets strukturieren den Amazon S3-Namespace auf der höchsten Ebene und werden auch für die Zugriffskontrolle eingesetzt. Überdies dienen sie im Rahmen der Erstellung von Nutzungsberichten als Auswertungseinheit.

Objekt: Objekte sind die Grundeinheiten, die in Amazon S3 gespeichert werden. Objekte bestehen aus Objekt- und Metadaten. Die Datenteile sind für Amazon S3 unverständlich. Metadaten bestehen aus mehreren Name/Wert-Paaren, die das Objekt beschreiben. Ein Objekt wird innerhalb eines Buckets eindeutig durch einen Schlüssel (Name) und eine Versions-ID identifiziert.

Schlüssel: Ein Schlüssel ist der eindeutige Bezeichner für ein Objekt in einem Bucket. Jedes Objekt in einem Bucket besitzt genau einen Schlüssel. Jedes Objekt wird durch die Kombination aus Bucket, Schlüssel und Versions-ID eindeutig identifiziert. Amazon S3 fungiert also als grundlegende Datenzuordnung zwischen „Bucket + Schlüssel + Version“ und dem Objekt selbst.